Compilation, Interpretation, Virtualisation etc. How Computer Programming Works - Part 5
Interpretation

I make boring tech look cool.
In part 4, I wrote about the problem of program portability; a program's code needs to be modified and recompiled for it to run on other platforms.
To solve this problem, this is where we introduce the concept of Interpretation. Before going further, we need to take a few steps back and reflect on our understanding of how programs run using this cheap illustration I made in Microsoft Paint😬:
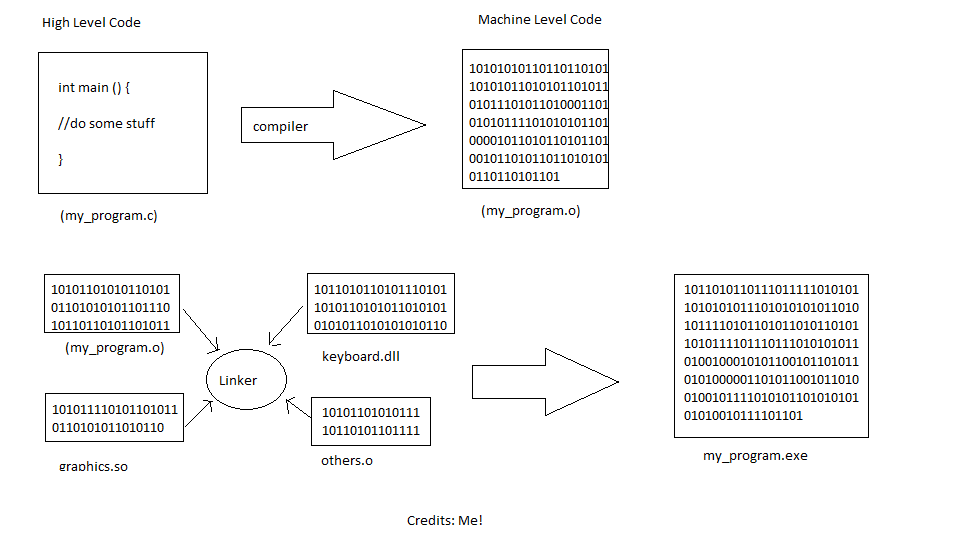
- Machines only understand machine language.
- Humans write in high level languages (these days).
- A compiler takes in ALL the code in HLL, converts them into machine format and stores that in a file called the object file. Basically.
- A linker takes the object file and combines it with some other required object files to produce the final executable file. -The end user runs the executable file, the program runs natively and they hopefully leave you a good review.
The approach of an interpreter is different. Remember, the goal is to be able to take some code in HLL and have it run on another platform without all the compilation and linking fusses. So let's go.
An interpreter is a computer program with various routines. One of these routine reads the source code line by line (or more appropriately, statement by statement) and instead of converting ALL the instructions to their native equivalents and writing that to an output (object) file, it actually executes the instruction itself before it continues to the next line. Let's go back to the compilation process one last time by looking deeply at what the instruction is doing at each line:
int a = 23;
For this single line, this is, fundamentally what the compiler is thinking:
- This programmer needs a memory space that is 16 bits (the size of a typical integer) large.
- This programmer then wants to store the binary equivalent of the decimal (number in base 10) number 23, which is 00...00010111 in that memory space.
- That sounds legit.
- The machine equivalent of " create 16 bits memory space and store 00...00010111 in it " is 0011 1111011011 0000000000010111. (Just as an example)
- I will write this to the object file when I have read and validated all the other instructions in this source file.
Things are more complex than I am making it seem; like the method for choosing the memory block to store our 23 decimal, how it makes use of the "a" identifier and so on are all beyond the scope of this series.
When an interpreter encounters an instruction, it executes it and suspends the reading of further instructions in the source file until the execution is complete. The process also involves linking on the fly: that is, every other binary dependency a specific instruction might need has either been linked with the interpreter or will be supplied by external libraries before loading it into memory. This makes an interpreted program not only portable, but also flexible. You can modify the source code of some programs while they are still being executed. Interpretation makes for easy prototyping; no more manual compilation or linking with native dependencies and you can even change a source file while it is still running.
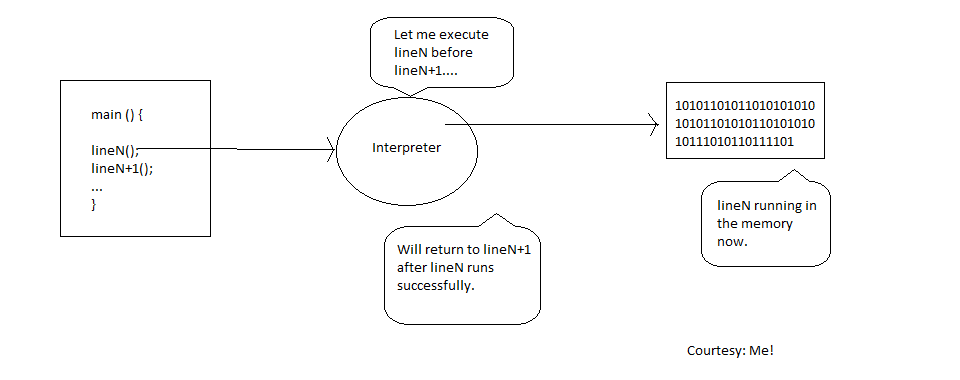
The way an interpreter executes these instruction depends on way it is designed.
Okay, before you call my Mum on me let me explain:
Take our previous example
int a = 23;
An interpreter could be designed in such a way that it converts the instruction into an internal representation as opposed to its equivalent machine representation so that instead of going into the memory to create 16 bits of memory space to store the decimal number 23 like in the previous example with a compiler, the designer might decide that every variable be stored in a data structure like a dictionary or something similar, to be retrieved when needed instead of a direct memory retrieval.
This is how basic interpreters are built, it eases the tasks for both interpreter designers and language users. For designers, you don't have to know about the details of the target machine's architecture, all you need do is to write a program that can represent the data and instructions as efficiently as possible. However, this method comes at the expense of speed, everything is too far from the machine, even the internal representation will still have to be processed programmatically. Programs that depend on this kind of interpretation can be very slow compared to their compiled counterparts.
To speed up execution without sacrificing flexibility, another approach is to directly convert an instruction to machine code at the time it's being read and executing that before moving to the next one. This is called just-in-time compilation or JIT, this means your code is converting to native representation just at the time when it is needed; and the type of compilation that involves writing all the source code's machine representation to an object file before execution is called ahead-of-time compilation or AOT.
So our programs with JIT will run much faster than their non JIT interpreters but there is we can still do to boost efficiency while maintaining the philosophies of flexibility, ease of writing programs and portability.
So in the next article, I will be discussing the concept of virtual machines, how they work, the need for them and where they fit in.



